
- English
- 日本語
Understanding the different PASS action behaviors
Last updated 2018-08-01
Passing with a request setting and with a cache setting triggers very different behavior in Varnish. Within VCL, passing with a request setting is the same as return(pass) in vcl_recv. Passing with a cache setting is the same as return(pass) in vcl_fetch. If you are familiar with Varnish 3+, passing with a cache setting is equivalent to return(hit_for_pass).
Using a request setting
Passing with a request setting translates within your generated VCL to return(pass) in vcl_recv. Varnish will not perform a lookup to see if an object is in cache and the response from the origin will not be cached.
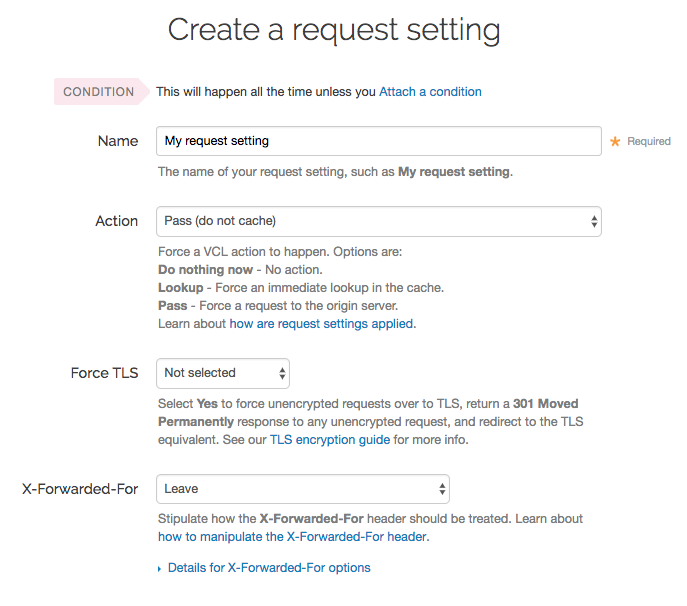
Passing in this manner disables request collapsing. Normally simultaneous requests for the same object that result in cache misses will be collapsed down to a single request to the origin. While the first request is sent to the origin, the other requests for that object are queued until a response is received. When requests are passed in vcl_recv, they will all go to the origin separately without being collapsed.
Using a cache setting
Passing with a cache setting translates within your generated VCL to return(pass) in vcl_fetch. At this point in the flow of a request, Varnish has performed a lookup and determined that the object is not in cache. A request to the origin has been made; however, in vcl_fetch we have determined that the response is not cacheable. In Fastly's default VCL, this can happen based on the presence of a Set-Cookie response header from the origin.
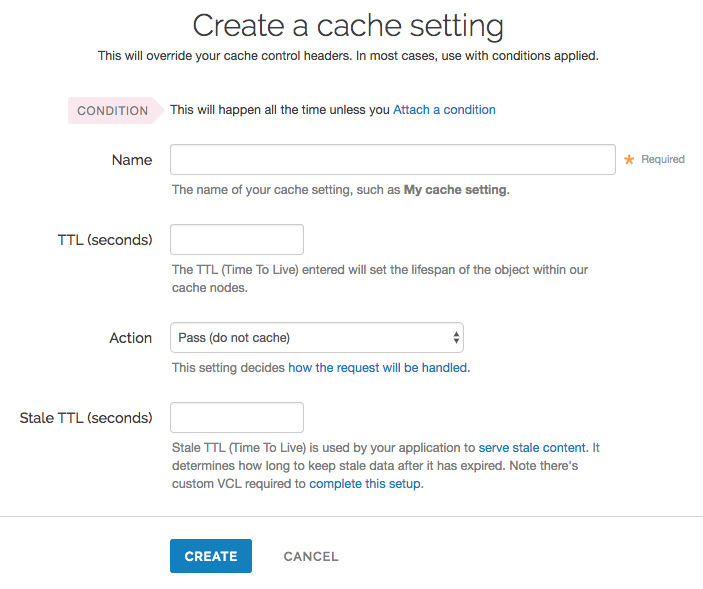
Passing in vcl_fetch is often not desirable because request collapsing is not disabled. This makes sense since Varnish is not aware in vcl_recv that the object is uncacheable. On the first request for an object that will be later passed in vcl_fetch, all other simultaneous cache misses will be queued. Once the response from the origin is received and Varnish has realized that the request should be passed, the queued requests are sent to the origin.
This creates a scenario where two users request an object at the same time, and one user must wait for the other before being served. If these requests were passed in vcl_recv, neither user would need to wait.
To get around this disadvantage, when a request is passed in vcl_fetch, Varnish creates what is called a hit-for-pass object. These objects have their own TTLs and while they exist, Varnish will pass any requests for them as if the pass had been triggered in vcl_recv. For this reason, it is important to set a TTL that makes sense for your case when you pass in vcl_fetch. All future requests for the object will be passed until the hit-for-pass object expires. Hit-for-pass objects can also be purged like any other object.
Even with this feature, there will be cases where simultaneous requests will be queued and users will wait. Whenever there is not a hit-for-pass object in cache, these requests will be treated as if they are normal cache misses and request collapsing will be enabled. Whenever possible it is best avoid relying on passing in vcl_fetch.
Using req.hash_always_miss and req.hash_ignore_busy
Setting req.hash_always_miss forces a request to miss whether it is in cache or not. This is different than passing in vcl_recv in that the response will be cached and request collapsing will not be disabled. Later on the request can still be passed in vcl_fetch if desired.
A second relevant variable is req.hash_ignore_busy. Setting this to true disables request collapsing so that each request is sent separately to origin. When req.hash_ignore_busy is enabled all responses will be cached and each response received from the origin will overwrite the last. Future requests for the object that are served from cache will receive the copy of the object from the last cache miss to complete. req.hash_ignore_busy is used mostly for avoiding deadlocks in complex multi-Varnish setups.
Setting both these variables can be useful to force requests to be sent separately to the origin while still caching the responses.
Do not use this form to send sensitive information. If you need assistance, contact support. This form is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
